Gemma3n: The Mobile-First Multimodal AI Revolution

What is The Gemma3n model ?
Imagine having the power of Google’s most advanced AI running directly on your smartphone—no internet required, no cloud delays, complete privacy. Google’s Gemma3n has turned this vision into reality, delivering a seismic shift that’s rewriting the rules of mobile AI forever.
This isn’t just another incremental upgrade. Gemma3n represents the first time truly sophisticated multimodal AI—capable of understanding text, images, audio, and video simultaneously—has been engineered from the ground up for everyday devices. Built on the same revolutionary foundation that will power the next generation of Gemini Nano, this mobile-first marvel brings cloud-level intelligence directly to your pocket while keeping your data completely private and accessible even when you’re offline.
Revolutionary architecture and technical innovation
At the heart of Gemma3n lies the MatFormer (Matryoshka Transformer) architecture, a nested design where larger models contain smaller, fully functional versions—like Russian Matryoshka dolls. The E4B model contains 8 billion total parameters but operates with 4 billion effective parameters, while the E2B model has 5 billion total parameters with 2 billion effective parameters. This elastic architecture enables real-time optimization between performance and memory usage, allowing developers to create custom-sized models between 2B and 4B parameters.
Google’s engineers cracked the code on mobile AI efficiency with breakthrough memory management that lets the model store less critical information in regular storage while keeping the essentials in active memory. This clever approach means the smaller E2B model needs just 2GB of RAM while the larger E4B runs smoothly on 3GB making them accessible on most modern smartphones. Advanced caching techniques also deliver 2x faster response times, ensuring snappy performance even on mobile hardware.

Multimodal capabilities and performance
Gemma3n’s multimodal prowess extends across text, audio, image, and video processing. The Universal Speech Model (USM) based audio encoder generates approximately 6 tokens per second, supporting up to 30 seconds of audio input at launch with capabilities for Automatic Speech Recognition (ASR) and Speech Translation, showing particularly strong performance for English, Spanish, French, Italian, and Portuguese.
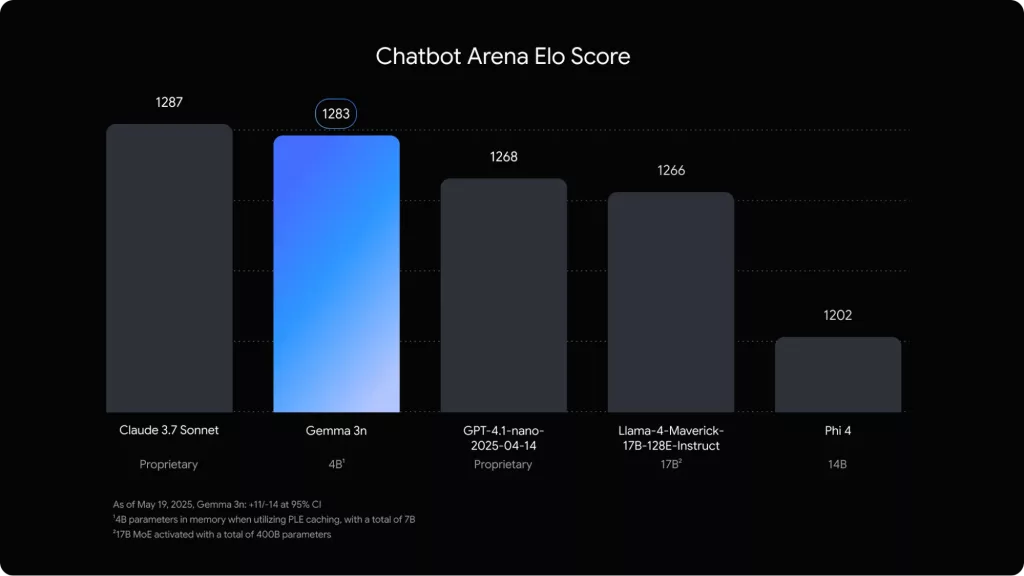
Visual processing leverages the new MobileNet-V5-300M encoder, delivering 13x speedup with quantization and a 4x smaller memory footprint compared to baselines. The encoder supports multiple resolutions (256×256, 512×512, and 768×768 pixels) and achieves up to 60 frames per second on Google Pixel devices. This efficiency comes from advanced architecture built on MobileNet-V4 blocks with Universal Inverted Bottlenecks and Mobile MQA.
Performance benchmarks demonstrate 1.5x faster response times on mobile compared to Gemma 3 4B, with the E2B variant providing up to 2x faster inference than E4B. The model excels across reasoning, factuality, multilingual understanding, and STEM/code generation tasks, consistently outperforming comparably-sized open model alternatives.
What makes Gemma3n special ?
Gemma3n breaks new ground as Google’s first open-source AI model designed specifically for mobile devices. While Google’s proprietary Gemini Nano is locked into Android and Chrome, Gemma3n gives developers complete freedom to customize and deploy these same cutting-edge capabilities anywhere they want.
The key advantage is simple: you get privacy-preserving on-device AI that rivals cloud-based performance, without the restrictions or costs of proprietary alternatives. Google is actively expanding partnerships with major chip makers like Qualcomm and Samsung to ensure Gemma3n runs optimally across different devices, with exciting new capabilities planned throughout 2025.
Conclusion
Google’s Gemm3n represents a fundamental advancement in democratizing powerful AI capabilities for on-device deployment. Its innovative MatFormer architecture, combined with PLE technology and multimodal encoders, enables unprecedented efficiency without sacrificing performance. For developers and AI enthusiasts, Gemma3n offers a compelling platform for building intelligent, privacy-preserving applications that operate seamlessly on everyday devices, marking a significant step toward ubiquitous, accessible AI technology.
How to run Gemma3n on Cordatus.ai ?
1. Connect to your device and select LLM Models from the sidebar.

2. Select vLLM from the model selector menu (Box1), choose your desired model, and click the Run symbol (Box2).

3. Click Run to start the model deployment.

4. Select the target device where the LLM will run.

5. Choose the container version (if you have no idea select the latest).

6. Ensure the correct model is selected in Box 1.

7. Set Hugging Face token in Box 1 if required by the model.

8. Click Save Environment to apply the settings.
Once these steps are completed, the model will run automatically, and you can access it through the assigned port.



