vLLM: Easy, Fast, and Cheap LLM Serving For Everyone

What is vLLM?
vLLM is a fast and easy-to-use library for LLM inference and serving. Initially developed at UC Berkeley’s Sky Computing Lab, vLLM has evolved into a community-driven project with contributions from both academia and industry.
vLLM is fast with:
- Efficient memory management with Paged Attention
- Fast model execution with CUDA
- Quantization methods
- Speculative Decoding
vLLM is flexible and easy to use:
- vLLM works with Huggingface models
- Supports NVIDIA GPUs
- Has an OpenAI-Compatible Server
- High-efficiency serving with various decoding algorithms, including parallel sampling, beam search, and more
vLLM’s innovative algorithms reduce GPU usage by 24 times compared to traditional methods (Huggingface Transformers) by shortening the duration with OS virtual memory design. As a result, vLLM has become very popular due to its high efficiency and low resource usage.
How Does vLLM Work?
To generate meaningful output, the model must understand the importance of each token in the context and its relationship with other tokens. In a typical transformers model, this contextualization is done as follows:
The meaning of the current token is found with the Query, and its relationship with other sentences is investigated. The compatibility of other tokens with this token is stored in the Key parameter. The model calculates a similarity score by comparing each query with the keys. These scores are combined with the Value, which represents the content of the token.
For example, consider the following sentence:
“It is a hot summer day, we should bring …”
The Query creates a question vector (query) corresponding to the word “bring”. The model searches for the meaning of the word “bring”. The other words in the sentence are represented as both Key and Value vectors. The similarity between the Query and Key vectors is calculated. The calculated attention scores are combined with the Value vector and averaged. As a result, the word “bring” is contextualized with words like “hot” and “summer”.
KV Cache in vLLM
In the KV Cache technique, the calculated Key and Value vectors are cached and used directly in subsequent operations without being recalculated. This allows the model to work faster and more efficiently, especially with long sequences.For example, if a user queries “What is the capital of India/Ireland,” the phrase “What is the capital of” is cached.
During KV Cache, 30% of the GPU memory is allocated, but not all of this allocated portion is used. This is a Memory Overallocation and Fragmentation problem commonly seen in OS memory management. For instance, if 16 MB of GPU memory is allocated to both Process A and Process B, but each only uses 14 MB, the remaining 2 MB of memory for each process remains unused and is wasted.

Figure: Memory allocation process
Paged Attention
In contrast, vLLM has developed the PageAttention algorithm. This algorithm aims to actively utilize the unused spaces allocated in GPU memory. The GPU is divided into pages, allowing dynamic memory management. Unused pages are released or used by other processes.Unlike KV Cache, which involves contiguous memory sharing, PageAttention utilizes non-contiguous memory sharing.
Additionally, vLLM optimizes the beam search process. In the traditional Beam Search algorithm, tokens for all words are generated and KV Cached for the word “bring” given in the example above. However, in the vLLM Beam Search method, since “bring” is the same for “bring water” and “bring ice,” the KV Cache created for “bring” is shared.
KV Cache involves contiguous memory sharing, whereas Paged Attention utilizes non-contiguous memory sharing.

Figure: vLLM performance compared to ORCA models
Other Features
Additionally, these features are designed to enhance both performance and scalability, making it easier to deploy large language models in production environments with minimal latency and maximum efficiency.
Optimized for PyTorch and CUDA: Supports optimized CUDA kernels, including integration with FlashAttention and FlashInfer
Quantization: Supports GPTQ, AWQ, INT4, INT8, and FP8
Tensor Parallelism: Provides support for tensor parallelism and pipeline parallelism for distributed inference
Speculative Decoding: A smaller model running in the background predicts the outputs that the vLLM model will generate. The main model then verifies and corrects these predictions, speeding up the process.
Flash Attention: Self-attention can be very costly. With FlashAttention, it is processed in blocks, making memory usage more efficient.
vLLM Architecture
vLLM provides a number of entrypoints for interacting with the system. The following diagram shows the relationship between them.

Figure: vLLM Entrypoints
The vLLM architecture is as follows:
An LLM model performs inference.
In the background, there is an OpenAI-Compatible API Server. This server is launched with the `vllm serve` command. Alternatively, it can also be run with the following Python command:
python -m vllm.entrypoints.openai.api_server –model
For more details, you can check the source code of vLLM API Server.

Figure: LLM Engine
The output of this server is processed by the `AsyncLLMEngine`. The main feature of this engine is that it performs operations asynchronously, allowing the computer to continue background processes and significantly reducing the likelihood of freezing.
All these components are unified under the `LLMEngine`. Its task is to take the incoming request and produce the appropriate output. This process consists of the following stages:
Input Processing: Incoming data is transformed into a format that the model can understand.
Scheduling: Operations are scheduled to efficiently utilize system resources.
Model Execution: The model generates predictions and results based on the given input.
Output Processing: Results from the model are post-processed before being presented to the user.
Conclusion
vLLM is a powerful and efficient library for LLM inference and serving, offering significant improvements in speed and resource usage. Its innovative algorithms, such as Paged Attention and KV Cache, optimize memory management and execution, making it a valuable tool for both academia and industry. With support for various models, GPUs, and advanced features like speculative decoding and tensor parallelism, vLLM stands out as a versatile and high-performance solution for large language model applications.
For more information and to get started with vLLM, visit the vLLM Github repository or official website .
Running vLLM in Cordatus
Why Use vLLM within Cordatus?
- 🚀 Optimized for both Jetson & x86: Cordatus intelligently selects the appropriate vLLM container optimized for your specific hardware architecture (arm64 for Jetson, amd64 for PC), ensuring compatibility and performance out-of-the-box.
- ⚡ High-Throughput Inference: Leverage vLLM’s state-of-the-art performance optimizations for fast, low-latency LLM responses, critical for real-time applications.
- 🔄 Seamless Integration: Forget manual installation and configuration headaches. Cordatus handles the entire vLLM deployment process automatically based on your selections.
- 💡 Scalable & Flexible: Whether targeting resource-constrained edge devices or powerful desktops, the Cordatus-managed vLLM adapts to deliver efficient performance.
Running Popular LLM Models (e.g. LLaMA, Qwen) with vLLM on Cordatus
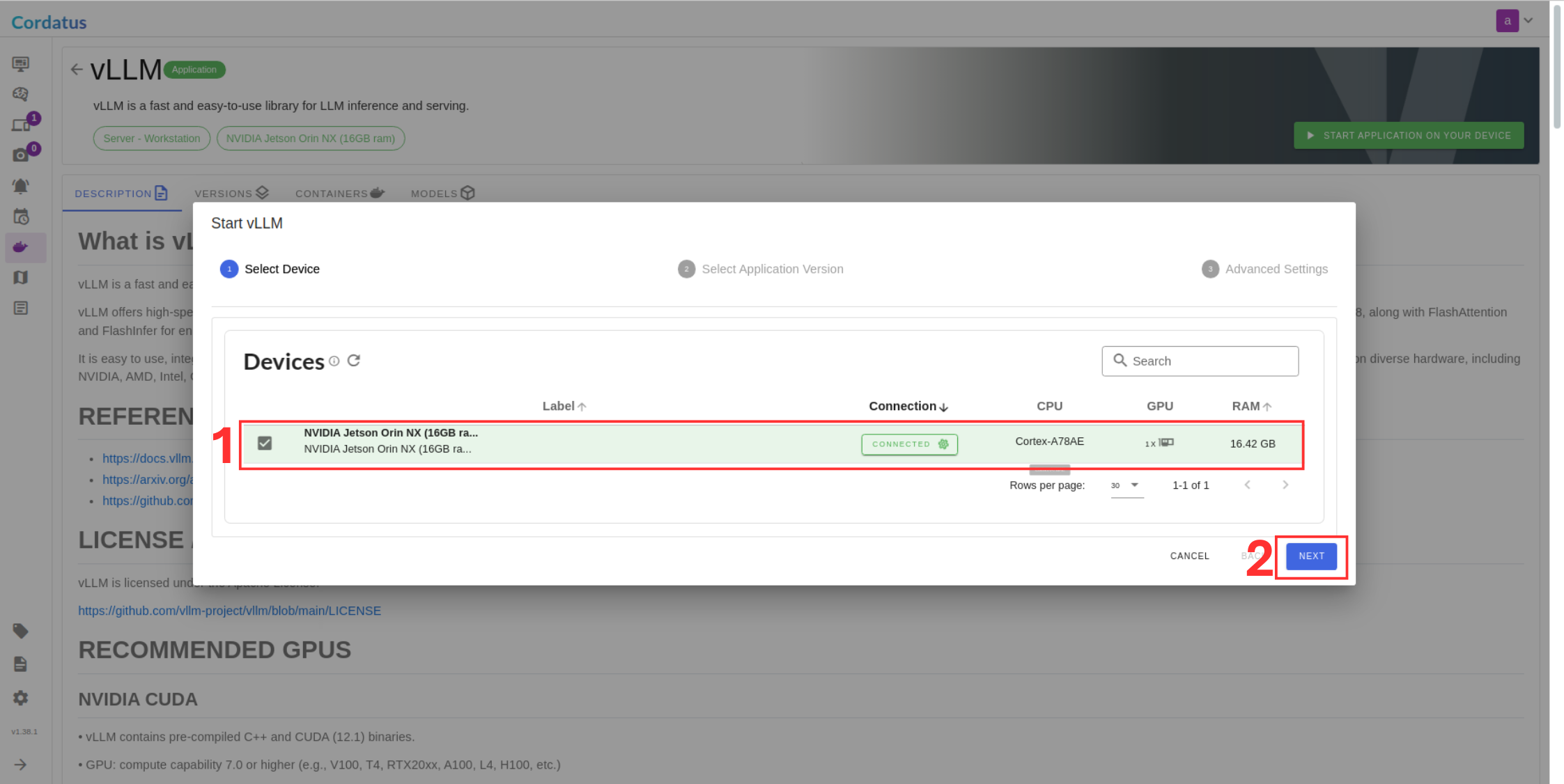
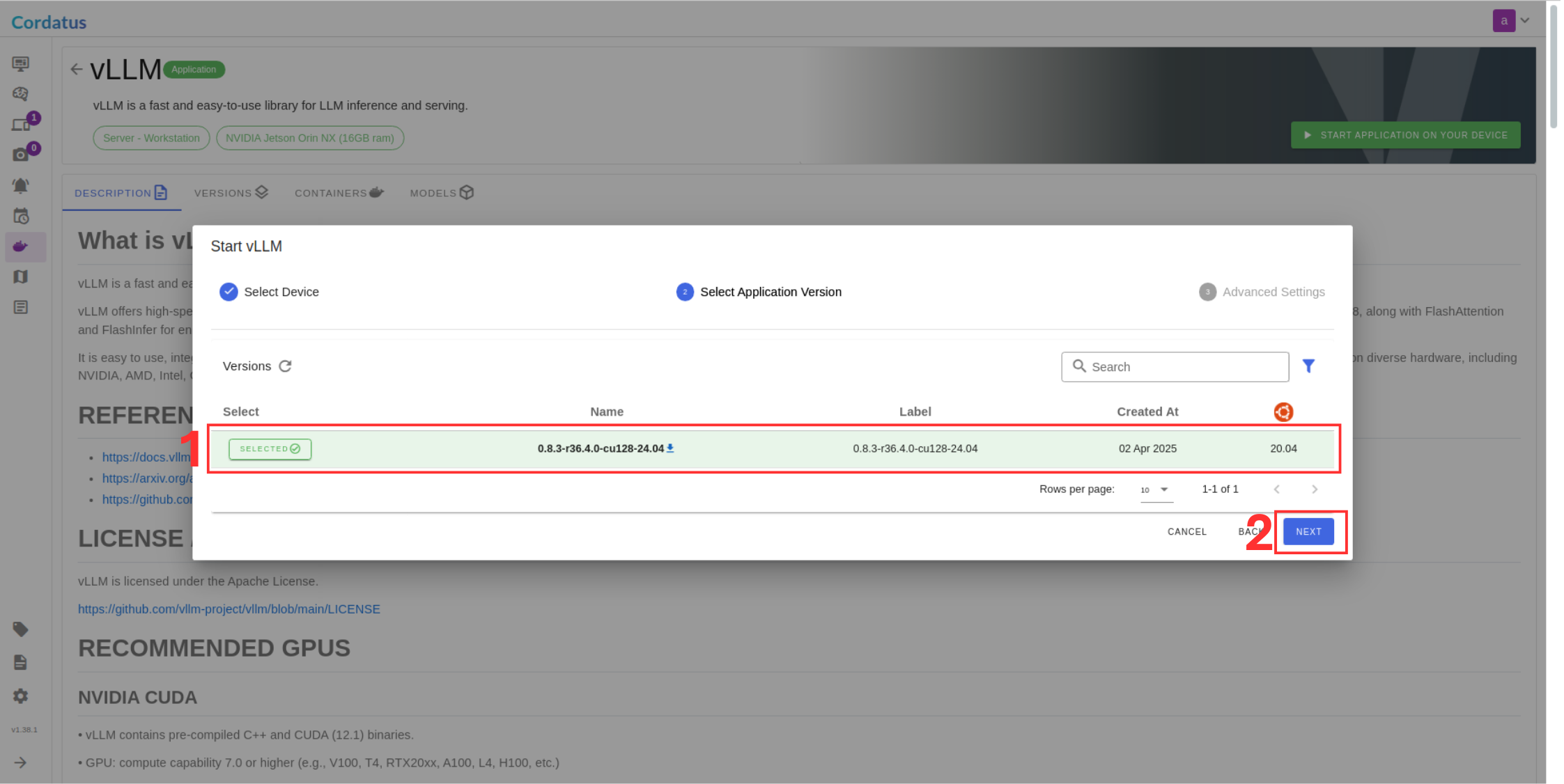
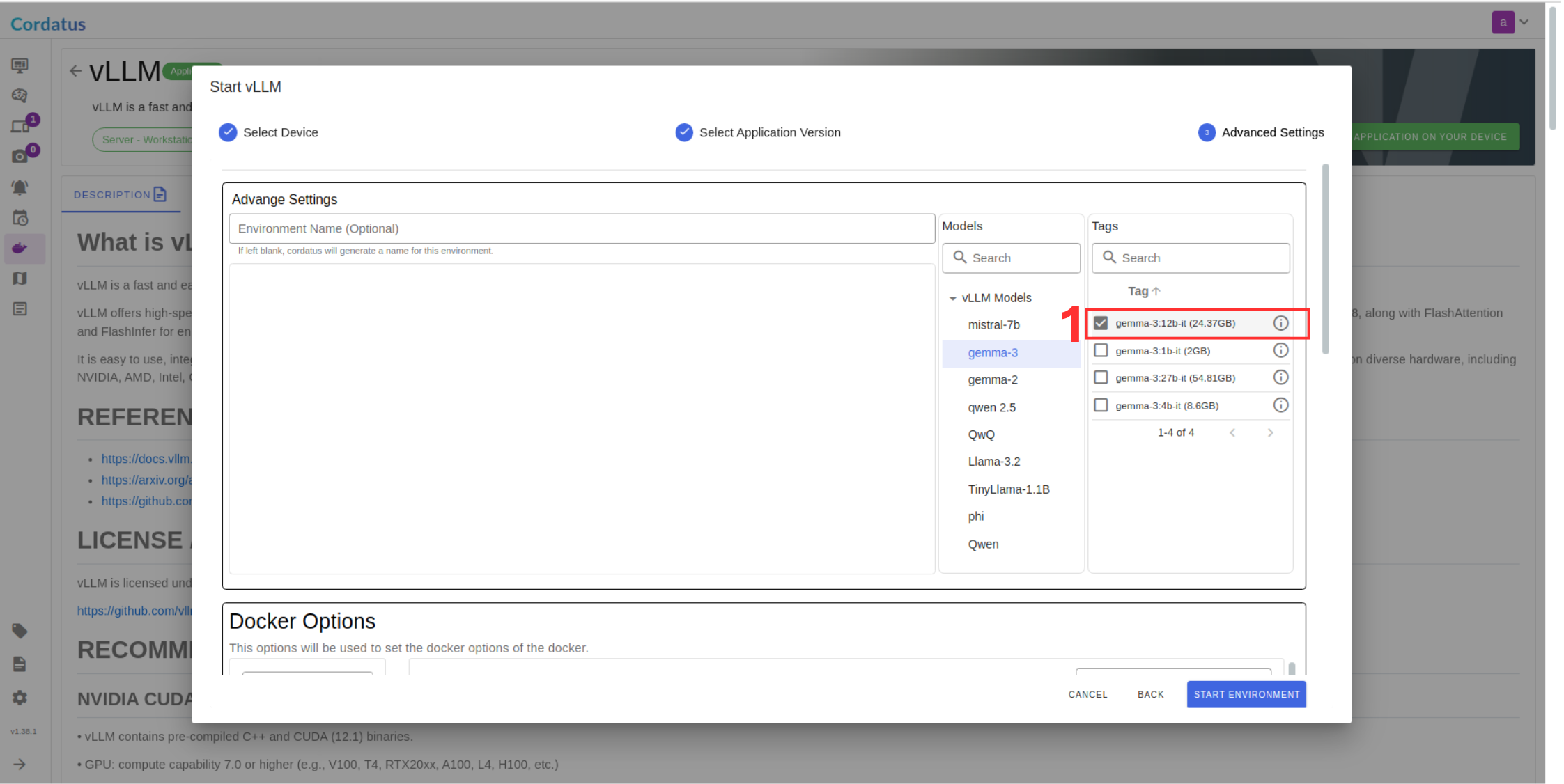
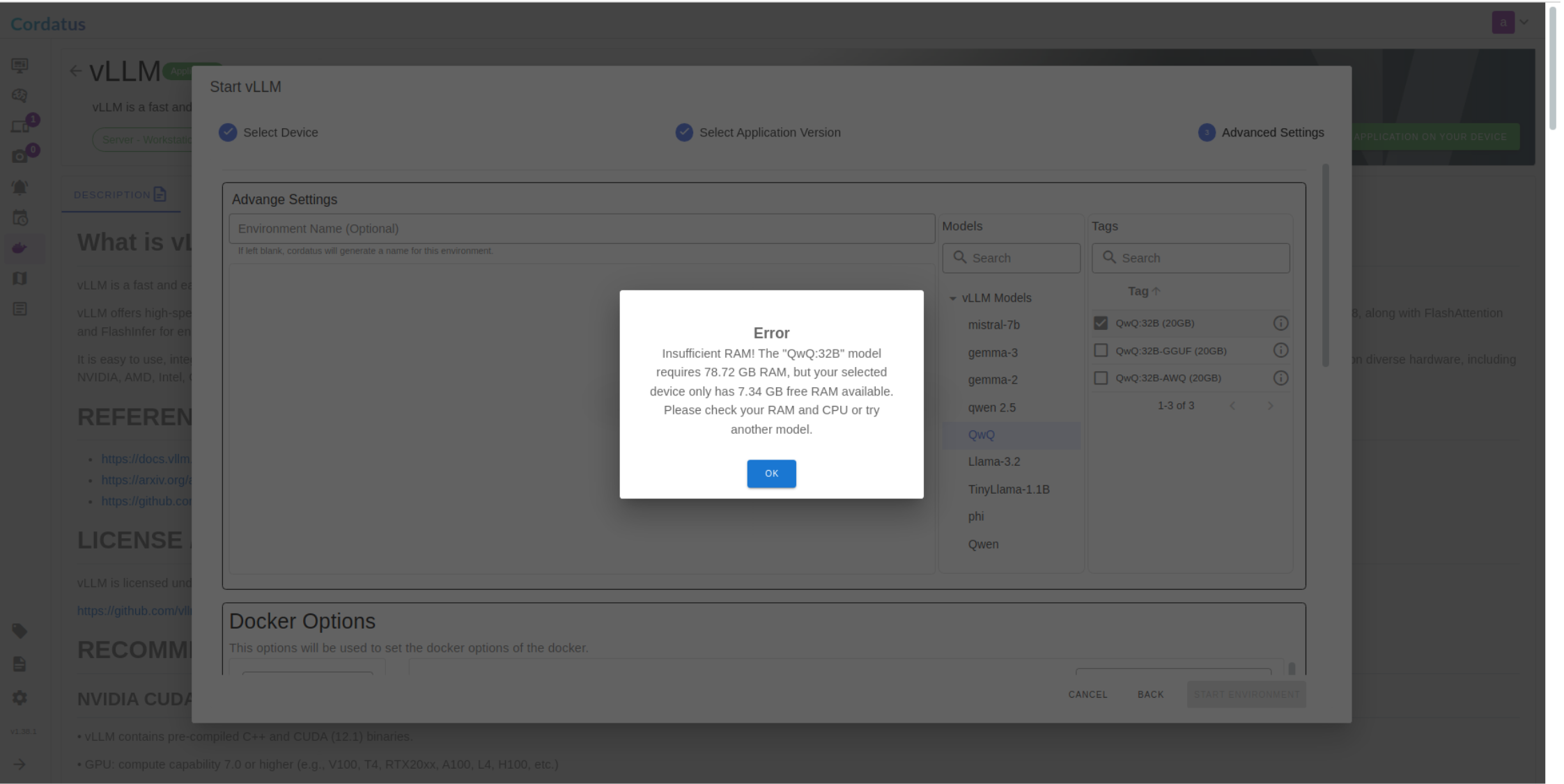
There are two methods for launching vLLM in Cordatus:
Method 1: Model Selection Menu
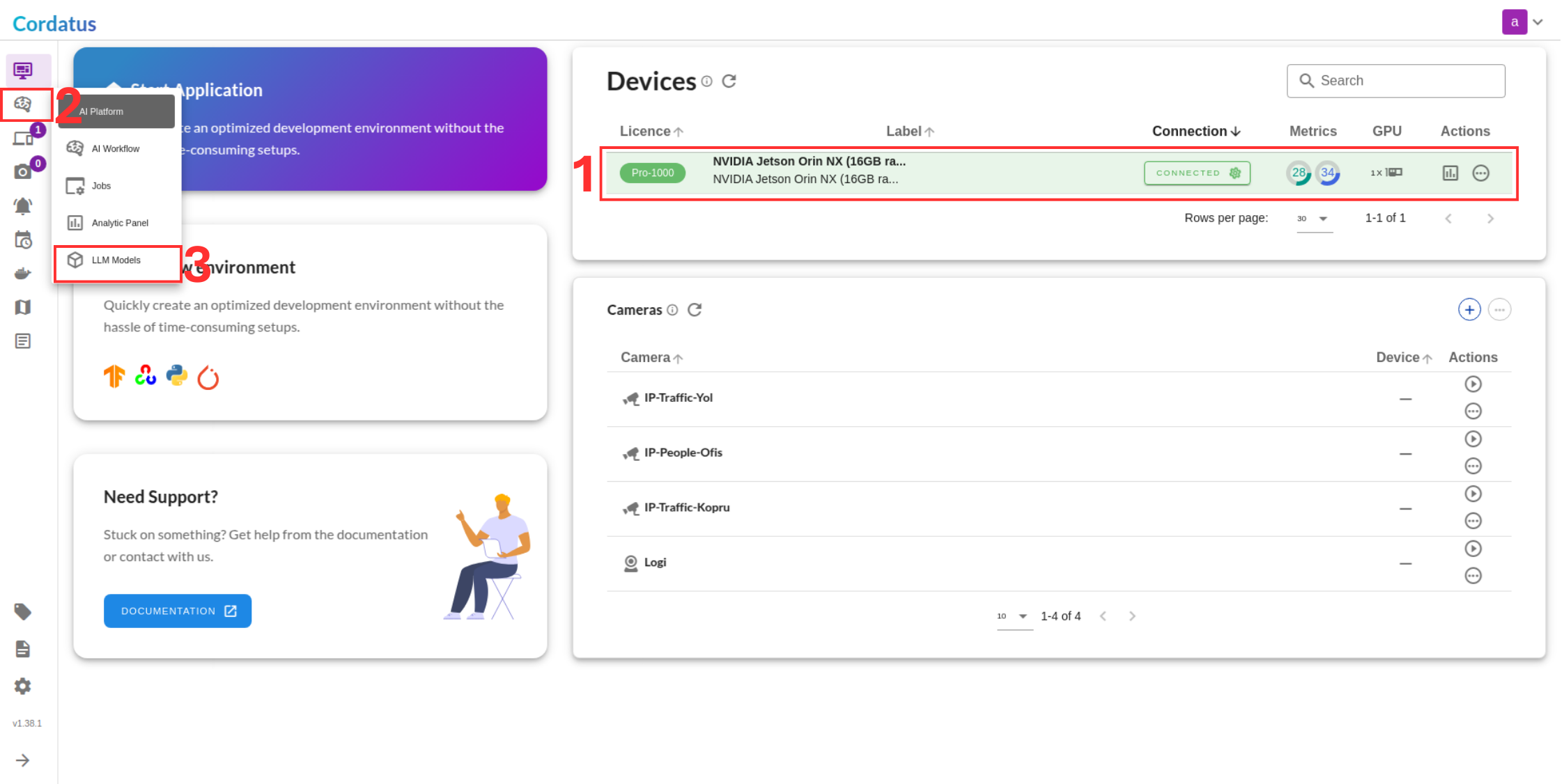
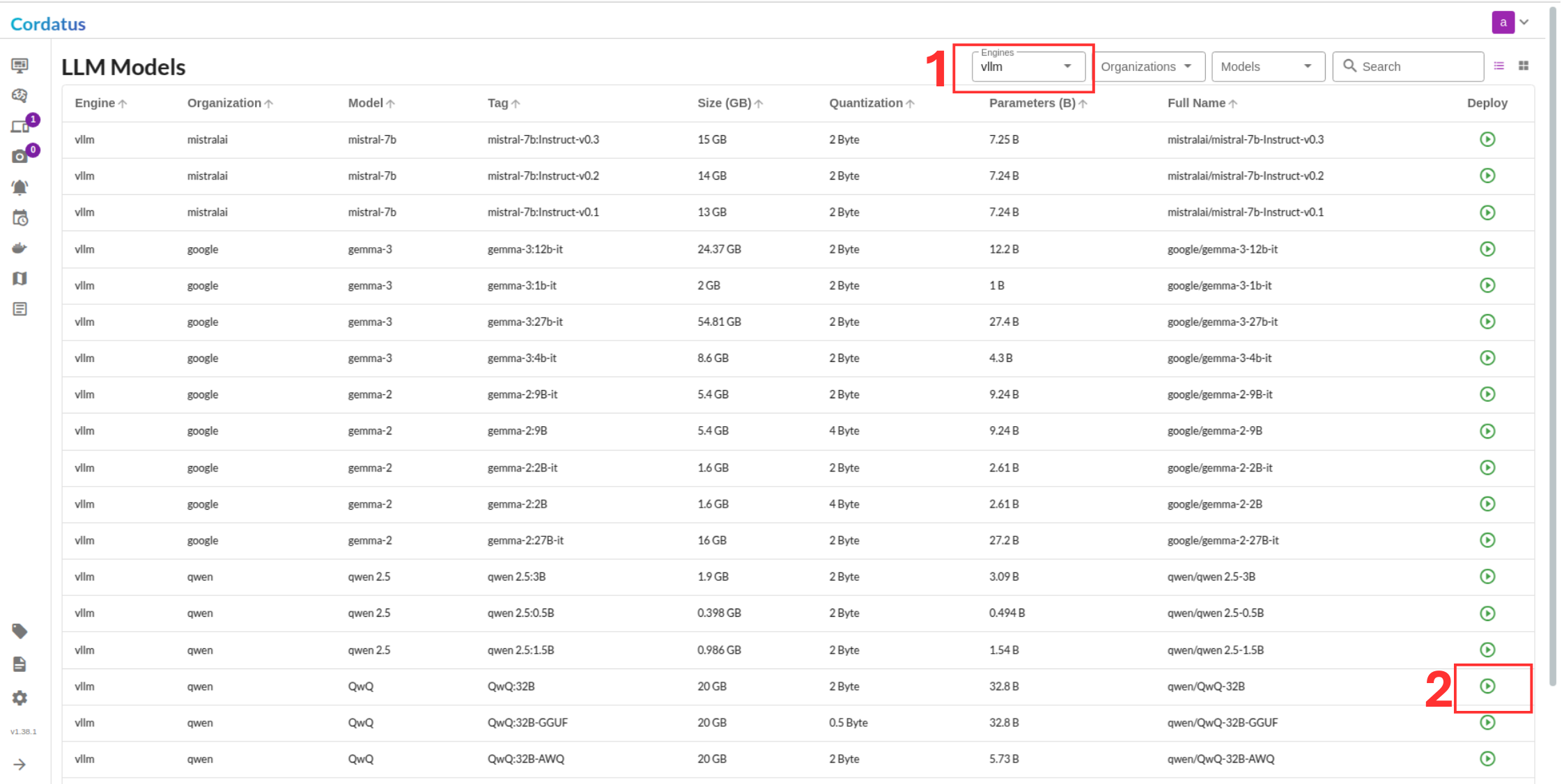
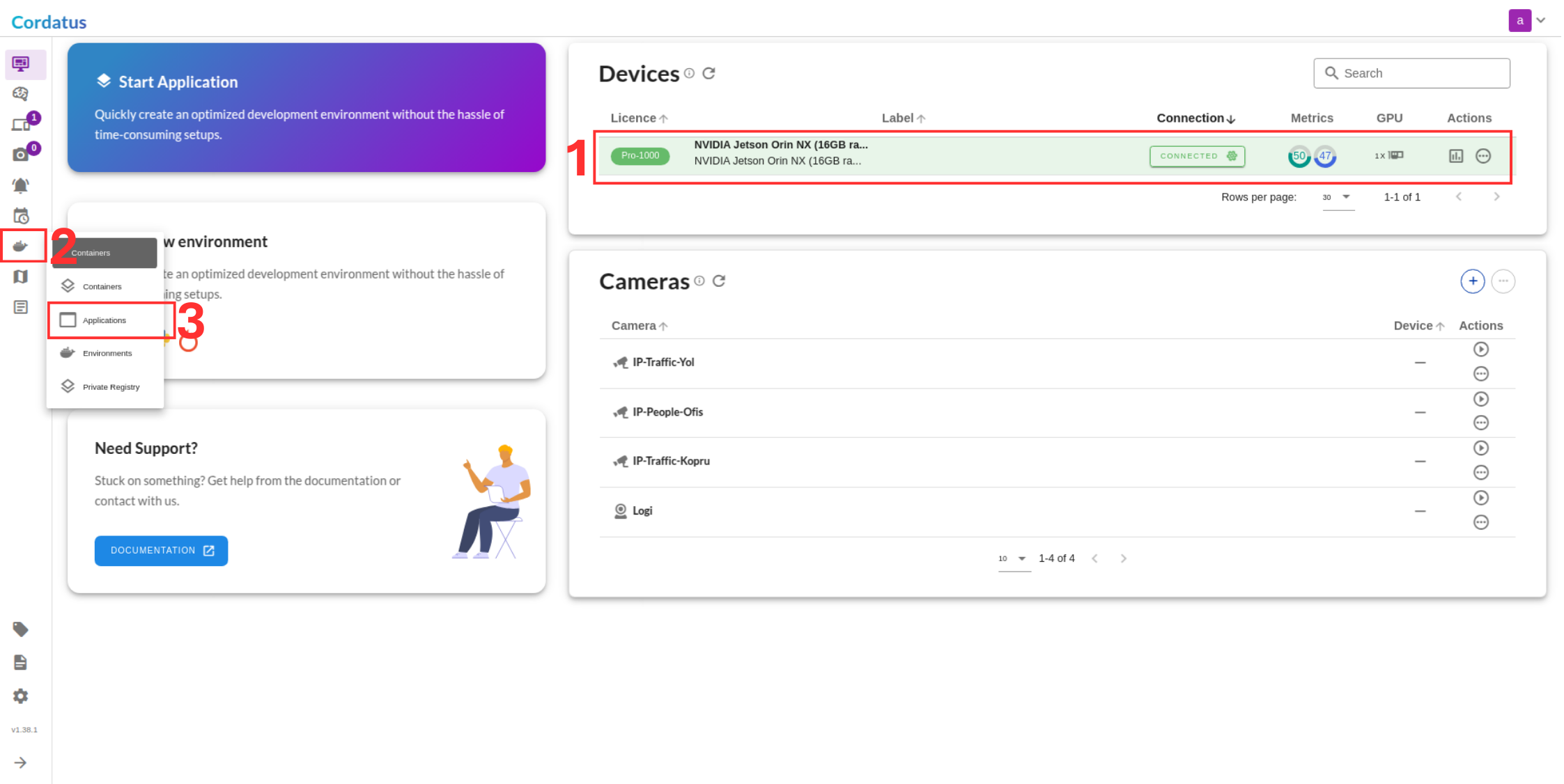
Method 2: Containers-Applications Menu
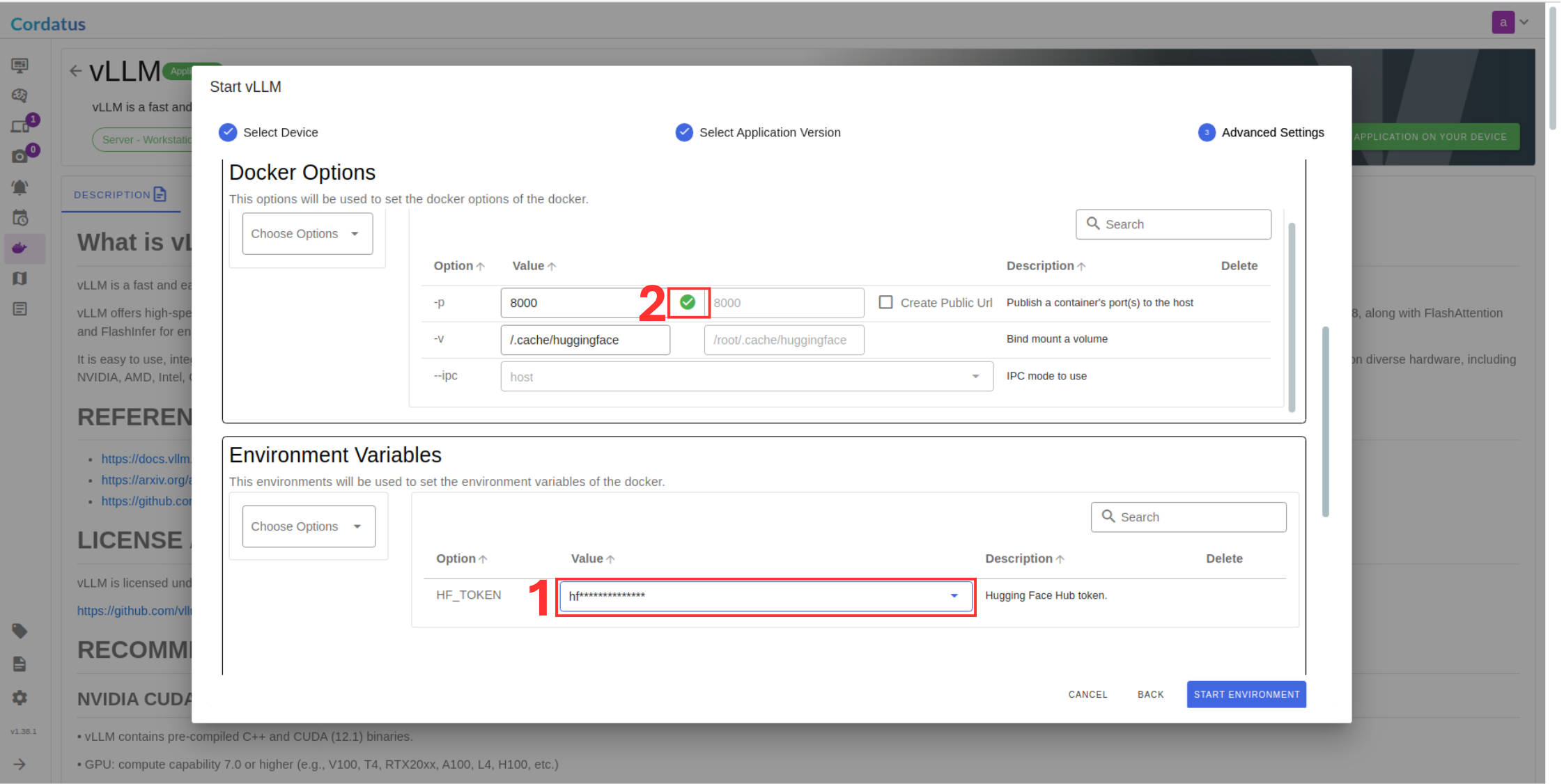
Configuring and Running the Model