

Ollama LLM: Get Up and Running with Large Language Models

What is Ollama?
To run the Ollama LLM, an isolated environment is created, ensuring no conflicts with other programs. This environment includes model weights, configuration files, and necessary dependencies. The model is downloaded locally and stored in the `~/.ollama` directory, allowing for offline use. This also provides strict data security, which is valuable for developers as your prompts remain private.
Ollama consists of a client and a server. The client is where the user interacts via the terminal. The server, written in “Go,” is implemented as a backend service with a REST API.
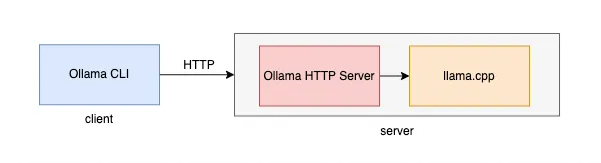
Figure 1: Ollama architecture
The server can be started through one of several methods: command line, desktop application (based on the Electron framework), or Docker. The client and server communicate using HTTP.
Ollama uses llama.cpp to execute LLM text generation. Llama.cpp is a library optimized for running LLaMA models on the CPU. Its lightweight structure allows large language models to run even on low-end devices. It is platform-independent and supports 4-bit and 8-bit quantization to reduce memory consumption and processing costs.
What are GGML and GGUF?
GGML is a model file format. Its primary purpose is to efficiently store and run large language models. It can store quantized versions of models (e.g., 4-bit or 8-bit) and is suitable for CPU-based inference. GGUF is a more advanced and flexible version of GGML. It offers better performance and, unlike GGML, is compatible with all models, not just Llama models. It is suitable for both CPU and GPU.

Figure 2: GGUF Model File Format
How Does Ollama Work?
The user starts the conversation via CLI (ollama run llama3.2). The CLI client sends an HTTP request to the ollama-http-server to get information about the model and reads the local “manifests” metadata file. If it doesn’t exist, the CLI client sends a request to the ollama-http-server to pull the model, and the server downloads it from the remote repository to the local machine.
The CLI first sends an empty message to the /api/generate endpoint on the ollama-http-server, and the server performs some internal channel handling (in Go, channels are used). The formal conversation begins: CLI sends a request to the /api/chat endpoint on the ollama-http-server. The ollama-http-server relies on the llama.cpp engine to load the model and perform inference (since llama.cpp also serves as an HTTP server).
Conclusion
Ollama is a powerful tool that allows users to run large language models efficiently and securely. Its isolated environment structure, local storage, and data security features stand out. The GGML and GGUF formats enhance model performance, while the llama.cpp library ensures high performance even on low-end devices. Ollama’s client-server architecture and HTTP-based communication make it easy for users to interact. These features make Ollama an indispensable tool for developers.
Running Ollama in Cordatus: Simple Local LLM Deployment
Ollama has gained immense popularity for making it incredibly simple to download and run powerful open-source Large Language Models (LLMs) locally. It packages models, configurations, and the serving runtime together for an effortless user experience. Cordatus further streamlines this process by managing the deployment of the Ollama service within a container, making it easy to get started on both NVIDIA Jetson edge devices and x86 PCs.
This guide explains how to launch and manage the Ollama service using Cordatus.
Why Use Ollama in Cordatus?
Unmatched Simplicity: Get the Ollama service running with just a few clicks, leveraging its famously easy model management system.
Broad Model Access: Once Ollama is running via Cordatus, you can easily pull and run models from Ollama’s extensive online library using its standard commands or API.
Managed Deployment: Cordatus handles the container setup, dependencies, and lifecycle management for the Ollama service.
Cross-Platform Compatibility: Cordatus ensures the correct Ollama container runs seamlessly on your supported hardware, whether it’s an NVIDIA Jetson (arm64) or a standard PC (amd64).
Standard API: Exposes the standard Ollama API (usually on port 11434) for integration with your applications or tools like Open WebUI.
Serving LLaMA 3, Mistral, and Qwen with Ollama Inside Cordatus
Method 1: Model Selection Menu
1. Connect to your device and select LLM Models from the sidebar.

2. Select ollama from the model selector menu (Box1), choose your desired model, and click the Run symbol (Box2).

Method 2: Containers-Applications Menu
1. Connect to your device and select Containers-Applications from the side bar.

2. Select ollama from the container list.

3. Click Run to start the model deployment.

Configuring and Running the Model
Once you have selected the model, follow these steps to complete the setup:
4. Confirm the device where the Ollama container will be deployed.

5. Choose the appropriate Ollama container image. Using the latest version is generally recommended.

6. Select the desired model.

7. Verify the network port for the Ollama API. The default is typically `11434`. Ensure it shows as available . If not check for conflicts or adjust if necessary/possible within Cordatus settings.
8. Click Jupyter notebook to enable if you need.

9. Click Save Environment. This saves your configuration and starts the Ollama service container on your device.
Success! The Ollama service is now running locally, managed by Cordatus.



