

Qwen 2.5 VL: Smarter Than Ever for Documents, Videos, and More

Qwen 2.5 VL is a powerful vision-language model (VLM) capable of understanding both text and visual content. Competing with models like OpenAI’s GPT-4o, it’s designed for advanced tasks like document analysis, object detection, and long video understanding. It strikes the perfect balance for prosumer and homelab users—high performance, low cost, and easy deployment.
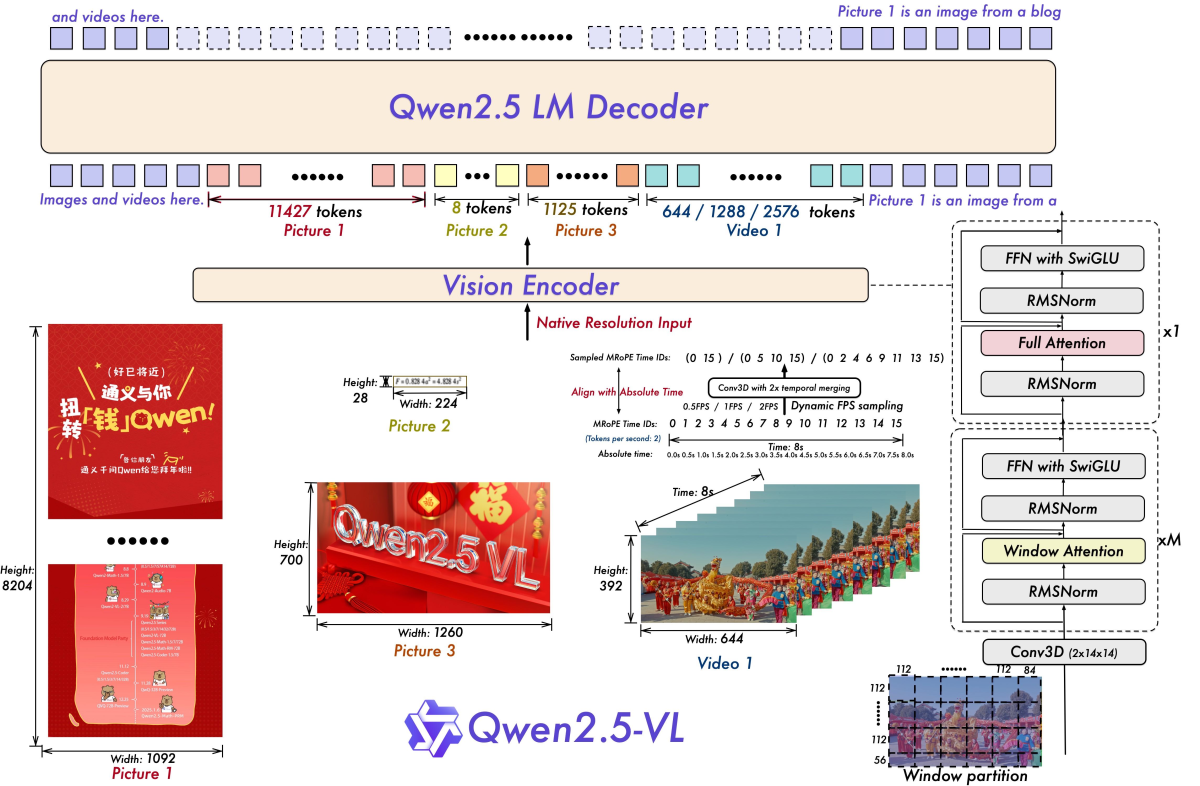
Qwen 2.5 VL is a next-generation vision-language model that processes images and videos natively—at their original resolution and temporal scale. As illustrated above, it integrates a powerful Vision Encoder with an advanced LM Decoder capable of handling diverse media inputs like documents, scenes, and long-form videos. With fine-grained attention mechanisms, including full and window attention, Qwen 2.5 VL delivers both high accuracy and speed, making it ideal for real-world applications where understanding complex visual data is critical. This foundation sets the stage for its standout capabilities in document parsing, object grounding, and video understanding.
Model Architecture
What Makes Qwen 2.5 VL Stand Out? Why Should You Use It?
-
Advanced Document Parsing (Omnidocument Recognition): It excels at processing complex documents like handwriting, tables, chemical formulas, and even music sheets.
-
Precise Object Grounding & Counting: It not only detects objects in images but also pinpoints their positions and counts them accurately—supports outputs in JSON and coordinate formats.
-
Ultra-Long Video Understanding: Capable of analyzing hours-long videos and extracting key event segments within seconds. A game-changer for video analysis.
-
Enhanced Agent Abilities: Features superior reasoning, decision-making, and grounding capabilities, optimized for both desktops and mobile devices.
-
Benchmark Performance: The 7B variant outperforms GPT-4o-mini in many benchmarks, while the 72B variant rivals GPT-4o itself.



